
最近在做mysql数据库的一些优化,主要是sql语句的优化。查阅了一些资料加上一些实战,这里简单做一下总结,水平有限,欢迎大家指正:
sql优化,一般有两方面:
优化io:
IO应该是数据库(尤其是数据量比较大的时候)时间开销最大的地方了,所以,IO优化非常重要,我们常用的方法是通过合理的使用索引来减少IO。
减少cpu运算:
除了IO,减少cpu运算也是一个优化sql的有效手段。order by,,group by,distinct,count …等都是比较消耗cpu的操作,但是,有时候为了更方便的得到想要的查询结果,这些操作还是必须有的。怎么办呢,其实,有时候我们可以将一些操作在程序里 实现,比如,我们有时候将两个表的中间结果放在map或者set中,通过简单的循环进行完成匹配,或者去重等操作。
我们的工作环境用的是 innodB,其实,我们用到的优化方式主要就是 先查看sql的执行计划,找出性能瓶颈,然后更合理的使用索引、选择更合适的语句过滤条件、用更轻快的查询替换容易导致查询中间结果臃肿的查询。
通过 explain+sql 我们可以了解sql 的执行计划,通过sql的执行计划,可以了解查询的性能瓶颈,简单对 explain 结果进行说明一下:
执行计划包含的信息有:

1、id:
表示查询中执行select子句或操作表的顺序
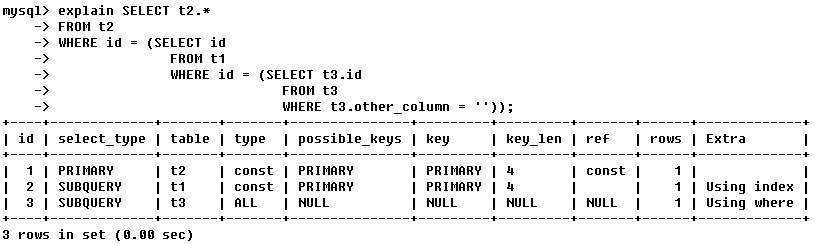
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行。
id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行。
2、select_type:
表示查询中每个select子句的类型,可以理解为语句的复杂程度。

SIMPLE:比较简单,查询中不含子查询或UNION
PRIMARY:若查询中包含子查询或UNION等,最外层查询为PRIMARY
SUBQUERY:在SELECT 或者 WHERE 后面跟的子查询,该子查询为SUBQUERY
DERIVED:在FROM后面的子查询为 DIRIVED
UNION:出现在UNION之后的SELECT,被标记为UNION
UNION RESULT:从UNION表获取结果的SELECT会被标记为UNION RESULT
还有一种相关子查询:
DEPENDENT SUBQUERY:是指引用了外部查询列的子查询,即子查询会对外部查询的每行进行一次计算。
3、type:
查询mysql表的方式,又称“访问类型”:
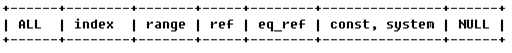
一般来说,从左向右,性能有差到好,但是,有时候强制使用不恰当的索引(ref)性能反而不如全表扫描(ALL)
4、possible_keys:
mysql可能使用的索引。
5、key:
在查询中实际用的索引。
6、key_len:
表示实际使用的索引的字节数,可通过该列计算查询中使用的索引长度,该值是通过索引定义计算得来。
7、ref:
表示查询中表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。

上面例子中:t1的col1匹配t2表的col1,col2匹配了一个常量(const)‘ac’,
8、rows:
表示mysql根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。这一项很重要,它基本能看出sql语句所要查询的行数,直观的显示了sql语句和使用索引的好坏。
9、Extra:
包含不适合在其他列中显示但是很重要的额外信息。
a、Using index
表示相应的select操作中使用了覆盖索引。
覆盖索引:表示包含所有满足查询需要的数据的索引。可以利用索引返回select要选的列表中的字段,而不必根据索引再次读取数据文件。
如果要使用覆盖索引,一定要注意select列表中只需取出需要的列,不可select * ,因为将所有字段一起做索引会导致索引文件过大,查询性能
下降。
b、Using where:
表示mysql服务器在存储引擎收到记录后进行 “后过滤”,如果查询没有使用索引,Using where的作用只是提醒我们mysql将用where子句来过滤结果集。
c、Using temporary:
表示mysql需要使用临时表来存储结果集,常见于order by和group by操作。
d、Using filesort:
mysql中无法利用索引完成的排序操作称为“文件排序”。
它不是使用排序的临时表太大导致内存放不下,从而放到硬盘上的“文件排序”,它只是排序(不用索引)。
另外,还可以使用 慢查询 和 profile 来查看sql语句的 磁盘IO和内存IO。现在我也不太了解,以后学习到了再为大家说明。
下面,我们说一下sql语句的执行顺序:
mysql 的sql 语句 执行顺序:
(8)SELECT (9) DISTINCT<select_list>
(1)FROM <left_table>
(3)<join_type>JOIN<right_table>
(2) ON<join_condition>
(4)WHERE<where_condition>
(5)GROUP BY<group_by_list>
(6)WITH{CUBE | ROLLUP} //mysql不支持CUBE操作
(7)HAVING<having_condition> //having是对分组条件进行过滤的筛选器
(10)ORDER BY<order_by_list>
(11)LIMIT<limit_number>
看,from才是第一个执行的,select比较靠后。每一步都会形成一个虚拟表,供下一步进行操作。
SELEC中,列的别名不能在SELECT中的其他别名表达式中使用。
SELECT 查询一共有3个过滤过程,分别是 ON 、WHERE、 HAVING 。ON 最先执行。
下面简单介绍一下索引及其优化:
大家都知道索引对于数据访问的性能有非常关键的作用,都知道索引可以提高数据访问效率。但是,索引也有其副作用:
索引需要额外的存储空间(这个好理解);
索引需要额外的维护成本(添加、删除数据都需要调整索引);
索引需要额外的访问开销。
关于索引,是不是越多越好?
如果数据表中的数据量很大,数据变化比较频繁,数据查询操作比较少,这样的场景是不适合多建索引的,可以说应该越少越好。
如果数据量非常小,那就更不用索引了,直接全表扫描就可以了。
如果磁盘空间成了稀缺资源,最好不要建太多索引。
如何选择合理的索引?
尽量使查找条件包含在索引中,用索引过滤更多的数据。
字段顺序很重要,尽量将过滤能力更强的条件字段放在前面。
当需要读取的数据量占比较大比例的时候,使用索引不一定会好于全表扫描的。
当查询中对应索引列的判断需要类型转换的时候,mysql是不会用索引的。
例如:
索引列 col1 的类型是 char 型
但是在我们用的时候 where col1 = 1
mysql需要进行对1进行转换,这时候是不会使用索引的。
直接使用 where col1 = ‘1’ 就可以使用索引了。
还要注意,一次查询只能用一个索引。
如果mysql自己选用的索引包含的条件字段不是很多,我们可以自己建一个索引,使用force index()就可以很好的提高查询性能。
下面介绍一下常见的误区(说明一下,以下主要是查阅资料总结出来的,因为自己写sql经验也比较少,就当是为将来写sql积累吧):
1、count(1)和count(primary_key) 优于 count(*)
在做统计行数的时候,大家可能会觉得count(1)和count(primary_key)优于 count(*),对于有些场景,这是个误区,因为mysql对count(*)做了相应的优化。
COUNT的时候,如果没有WHERE限制的话,MySQL直接返回保存有总的行数,而在有WHERE限制的情况下,总是需要对MySQL进行全表遍历。
1.任何情况下SELECT COUNT(*) FROM tablename是最优选择;
2.尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种查询;
3.杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现。
2、count(column) 和 count(*) 是一样的
这两者不一样的,count(column) 表示 column 列不为null的行数,count(*)是指结果集总行数
3、select a,b from … 比 select a,b,c from … 可以让数据库访问更少的数据量
mysql数据库存储的时候,采用行存储,但是每次取数据是按页取到内存,一般为4KB,8KB… 大多数时候,每个IO单元中存储了多行,每行都是存储了该行的所有字段
(lob等特殊类型字段除外)。当然,如果字段是通过索引查询,情况就不一样了。
4、order by 一定需要排序操作
我们知道索引数据实际上是有序的,如果我们的需要的数据和某个索引的顺序一致,而且我们的查询又通过这个索引来执行,那么数据库一般会省略排序操作,而直接将数
据返回,因为数据库知道数据已经满足我们的排序需求了。
实际上,利用索引来优化有排序需求的 SQL,是一个非常重要的优化手段
一些原则:
1、尽量少join
可以通过在程序中将多个表中间结果进行操作,达到想要的效果。
2、尽量少用排序
太消耗cpu了:
不必要的话就不要排序。
利用索引排序。
尽量对更少的字段排序。
3、尽量少用select *
由于取数据是按页,基本整行的数据都会取出来,这里不是考虑io的消耗,而是对order by 等操作,全部列属性取出来会对排序等操作产生影响。
4、 尽量用 join 代替子查询
相比于子查询,join的性能要好一些。
5、对于相关子查询
有时可以通过派生表来进行重写,以避免子查询与外部子查询的多次比较操作。
6、尽量少用or
mysql优化器对or没有太好的优化,可以使用IN、union 或 union all 代替or。
7、尽量用 union all 代替 union
union 和 union all 的差异主要是前者需要将两个(或者多个)结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的 CPU 运算,
加大资源消耗及延迟。所以当我们可以确认不可能出现重复结果集或者不在乎重复结果集的时候,尽量使用 union all 而不是 union。、
8、尽量早过滤
前面已经提到了,将过滤效果更好的条件判断放到前面。
9、避免类型转换
类型转换需要消耗cpu,所以,在数据库设计的时候尽量将一些列属性的类型设计的更加合理。
10、优先优化高并发的 SQL,而不是执行频率低某些“大”SQL
一旦出问题,并发度高的sql将成为灾难,所以,尽量优化并发度高的sql
11、用>=替代>
12、用表连接替换EXISTS
通常来说 , 采用表连接的方式比EXISTS更有效率
13、从全局出发优化,而不是片面调整
14、尽量对每一条sql都执行explain或者 profile
做到心中有数。
今天先整理这么多吧,感谢王扬大师,感谢胡中泉和简朝阳大师!



相关推荐
MySQL性能优化总结.pdf
总结了mysql优化的一些内容:例如btree索引,hash索引,聚簇索引和费举措索引,多列索引、重复索引和冗余索引等如何用,count、unicon等优化查询的方法。。。
介绍了MYSQL的优化方法,以及常用工具的使用方法。 大家都反映分数要的太高了,自己整理了MYSQL的优化。希望能得到一些积分来下载其它的学习资源,为了方便大家现在免分放送了,大家可以互相学习。
课程内容进行了精华的浓缩,有四大内容主旨,MySQL架构与执行流程,MySQL索引原理详解,MySQL事务原理与事务并发,MySQL性能优化总结与MySQL配置优化。课程安排的学习的教程与对应的学习课件,详细的学习笔以及课程...
Mysql基础性能优化思维导向图 (其中包括:mysql基础、mysql性能优化、mysql锁机制和主从复制) 文件名称:MySQL基础与性能优化总结.xmind
mysql性能优化 缓解数据库压力
2023最新mysql的sql语句优化方法技巧面试题总结.docx2023最新mysql的sql语句优化方法技巧面试题总结.docx2023最新mysql的sql语句优化方法技巧面试题总结.docx2023最新mysql的sql语句优化方法技巧面试题总结.docx2023...
Mysql数据库优化总结-飞鸿无痕-ChinaUnix博客................................................................................................................
mysql5.6性能优化总结
数据库优化方案整理总结,适合新手看看,包括查询优化,数据库索引优化等等。数据库优化方案整理总结,适合新手看看,包括查询优化,数据库索引优化等等。
课程大纲: 第1课 数据库与关系代数 综述数据库、关系代数、查询优化...再次回到理论,从理论的高度总结关系代数理论与MySQL查询优化实践的关系。真正认识、掌握MySQL的查询优化技术,大步流星步入查询优化的高手之列。
mysql优化总结,可以参考学习下
Mysql 执行优化 2 认识数据索引 2 为什么使用数据索引能提高效率 2 如何理解数据索引的结构 2 优化实战范例 3 认识影响结果集 4 影响结果集的获取 4 影响结果集的解读 4 常见案例及优化思路 5 理解执行状态 7 常见...
mysql优化教程总结,对于入门的学员来说分厂有用!可以下载
自己工作总结希望可以有用。。包括在网上参考后。自己实用的。。
mysql 优化 一点点个人总结
Mysql百万级以上查询优化总结,,对mysql表优化、索引优化
mysql数据库优化
MySQL高级开发优化培训总结。IBM中国区数据库专家外训资料。
mysql性能优化的总结,从各个方面对sql的优化进行了总结,感觉是很好的性能优化的摘要总结,所以上传共享出来,绝对的硬货。绿色版,解压直接用,方便程序猿